안녕하세요
이번시간에는 스크래핑과 크롤링에 대해서 알아보겠습니다.
우선 스크래핑과 크롤러라는 단어가 생소하실 텐데
웹 스크래핑이란 HTML로 구성된 웹 사이트의 페이지에서
자동으로 정보를 추출할 수 있는 것을 뜻하고 소스코드를 읽어서
필요한 데이터를 원하는 데이터 형식으로 저장합니다.
웹 크롤링이란 웹페이지를 자동 탐색하고 수집하는 것을 뜻합니다.
크롤러라고 불리는 프로그램이 다양한 웹 사이트를 방문하여
페이지의 내용과 링크를 추출해서 데이터베이스를 구축합니다
라이브러리 설치하기
pip install bs4 requests
HTML 살펴보기
우선 네이버에서 "애플"을 검색하게 되면
검색결과가 출력되는데요
F12키를 누르면 페이지가 구성되어 있는 요소들을 살펴볼 수 있습니다.
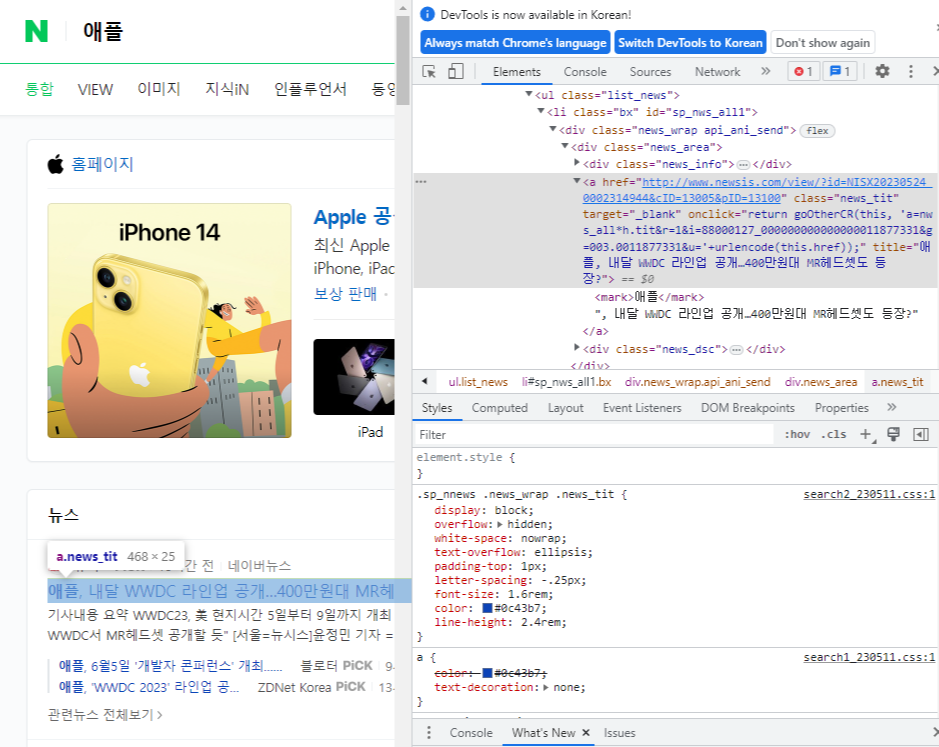
CTRL+SHIFT+C를 누르고 제목에 마우스를 가져가면 a.news_tit라는 문구가 보입니다
바로 이것이 네이버 뉴스의 제목을 뜻하는 요소입니다
바로 실습을 해보도록 하겠습니다
웹 크롤링 예제
import requests
from bs4 import BeautifulSoup
# 키워드를 바꿔서 검색 할 수 있게끔 get_news 함수를 선언
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# data에 네이버 검색창에 입력한 keyword로 검색한값이 저장
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis:
news = li.select_one('a.news_tit')
print(news.text, news['href'])
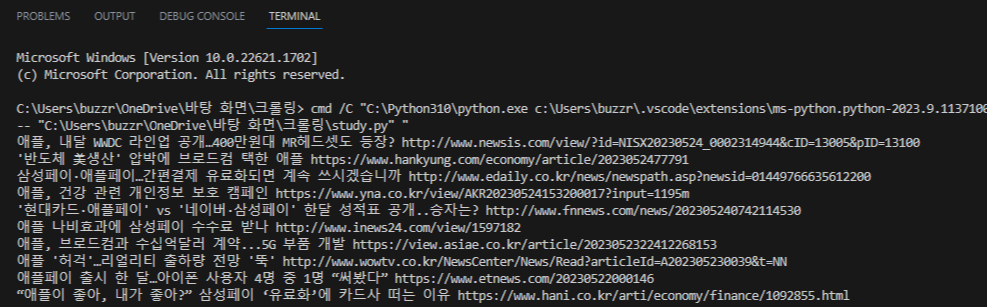
get_news('애플')위 코드의 실행 결과는 아래와 같다
엑셀로 저장하는 방법
이것도 라이브러리를 설치해 줘야 합니다
pip install openpyxl라이브러리를 설치했으면 간단한 코드로 엑셀을 다루는 방법 감 잡아봅시다.
from openpyxl import Workbook
wb= Workbook()
sheet = wb.active
sheet['A1'] = 'hello world!'
wb.save("샘플.xlsx")
wb.close()코드는 간단하니 일단 실행시켜 봅니다.
결과는 아래와 같습니다.

같은 경로에 우리가 지정한 샘플.xlsx 파일이 생성되었습니다
이것을 열어보면
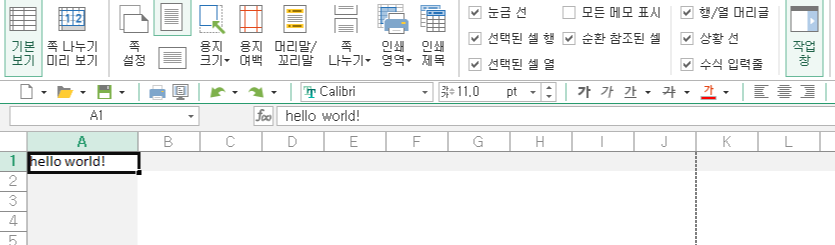
우리가 프로그램에서 지정했던 A1셀에 'hello world!'가 들어가 있는 걸 확인할 수 있습니다.
크롤링된 데이터를 엑셀파일로 저장하는 방법
위에 간단한 예제가 이해가 된다면
이제 응용해서 두 가지 실습했던 소스를 합쳐보도록 합시다.
크롤링된 데이터를 배열을 이용해
애플, 삼성, 현대, 기아 이렇게 각각 파일로 저장하는 소스코드입니다
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
def get_news(keyword):
wb=Workbook()
sheet=wb.active
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis:
news = li.select_one('a.news_tit')
row=[news.text, news['href']]
sheet.append(row)
wb.save(f"news/{keyword}.xlsx")
wb.close()
keywords=['애플','삼성','현대','기아']
for keyword in keywords:
get_news(keyword)이걸 실행하게 되면
애플.xlsx, 삼성.xlsx, 현대.xlsx, 기아.xlsx 이렇게 각각 엑셀파일로 저장됩니다.
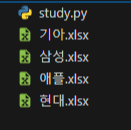
바로 이렇게 말이죠
현재는 같은 폴더에 저장이 되지만
다른 폴더에 저장하기를 원하시면
반드시 먼저 폴더를 생성한 후
wb.save(f"{keyword}.xlsx")
이 부분을
wb.save(f"news/{keyword}.xlsx")
이렇게 입력해 주시면
(저는 news라는 폴더를 만들었습니다)
news폴더 안에 파일이 생성되는 것을 확인하실 수 있습니다
아래는 생성된 파일중 하나인 "기아.xlsx"를 열어본 모습입니다

'Python > 업무 자동화' 카테고리의 다른 글
| [파이썬]selenium 을 활용한 네이버 자동 로그인(최신문법) (7) | 2023.05.31 |
|---|---|
| [파이썬]selenium을 활용한 구글 이미지 자동 다운로드(최신문법) (6) | 2023.05.26 |